



Latest News

Cities Skylines 2 apologies continue as recent DLC gets refunded
Cities Skylines 2 apology department has been called into action again as the floundering city sim, the sequel to one of the best city sims of all time, continues to disappoint at every turn. Fans of the game are getting resigned to the fact that developer Colossal Order is really struggling with this one and…















Artificial Intelligence

The Implication of AI in Crypto Trading
Brad AndersonFormer editor
Cryptocurrency

RBNZ Explores Introduction of Central Bank Digital Currency
The Reserve Bank of New Zealand (RBNZ) has announced that it is exploring the introduction of a central bank digital currency (CBDC), often referred to as "digital cash." This move comes as the RBNZ aims to address the challenges posed...
Radek ZielinskiTech Journalist

GBTC Bitcoin ETF holdings drop before halving
Radek ZielinskiTech Journalist



Entertainment

Technology

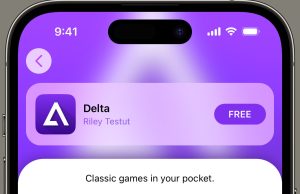
iPhone App Store competitor launches with a Nintendo 64 emulator
The first third-party Apple iOS app store is now live in the European Union, following the introduction of the Digital Markets Act (DMA) which has forced Apple and other platforms to open up their software marketplaces. AltStore PAL is an...
Sophie AtkinsonTech Journalist




AR / VR
Smartphones


We are an award-winning tech website where trusted research and expert knowledge come together
Since 2003, we have helped millions of people learn how to solve tech problems large and small. We work with credentialed experts, a team of trained researchers, and a devoted community to create the most reliable, comprehensive and delightful content on the Internet.
1M
Monthly Readers1.4M
Followers on X35K
ArticlesTrusted
for 20 years5000+
research hrs100+
EXPERT CONTRIBUTORSPopular Topics
Get the biggest tech headlines of the day delivered to your inbox
Explore the latest in tech with our Tech News. We cut through the noise for concise, relevant updates, keeping you informed about the rapidly evolving tech landscape with curated content that separates signal from noise.
Explore tech impact in In-Depth Stories. Narrative data journalism offers comprehensive analyses, revealing stories behind data. Understand industry trends for a deeper perspective on tech's intricate relationships with society.
Empower decisions with Expert Reviews, merging industry expertise and insightful analysis. Delve into tech intricacies, get the best deals, and stay ahead with our trustworthy guide to navigating the ever-changing tech market.