



Latest News
Steam closes refund policy loophole to stop Advanced Access gamers taking huge advantage
While not exactly a new phenomenon, some games did it almost a decade ago, the increase in the number of games offering gamers the chance to play the game up to three days early in exchange for paying a premium fee certainly seems more prevalent than ever before. Steam’s Refund Policy, while not overly generous…















Artificial Intelligence

Google AI Gemini to receive real-time responses in app
Ali ReesTech journalist

Cryptocurrency

New Token Based Degen Club ($BDC) Pumps 600% On Launch Day To $1.4M Market Cap
New token Based Degen Club ($BDC) token pumped from $200K to an over $1.2M FDV in less than 12 hours of its launch yesterday, a 675% increase. $BDC currently holds a $1.37M FDV just under 24 hours from its listing....
James SpillaneCrypto Writer


Entertainment

Technology
Microsoft launches its smallest AI model yet: Phi-3 Mini
Microsoft has launched its smallest AI model yet, Phi-3 Mini, the first of a trio of lightweight models. With more and more AI models coming onto the market, Microsoft is journeying into models that are trained on smaller-than-usual datasets. The...
Rachael DaviesTech Journalist
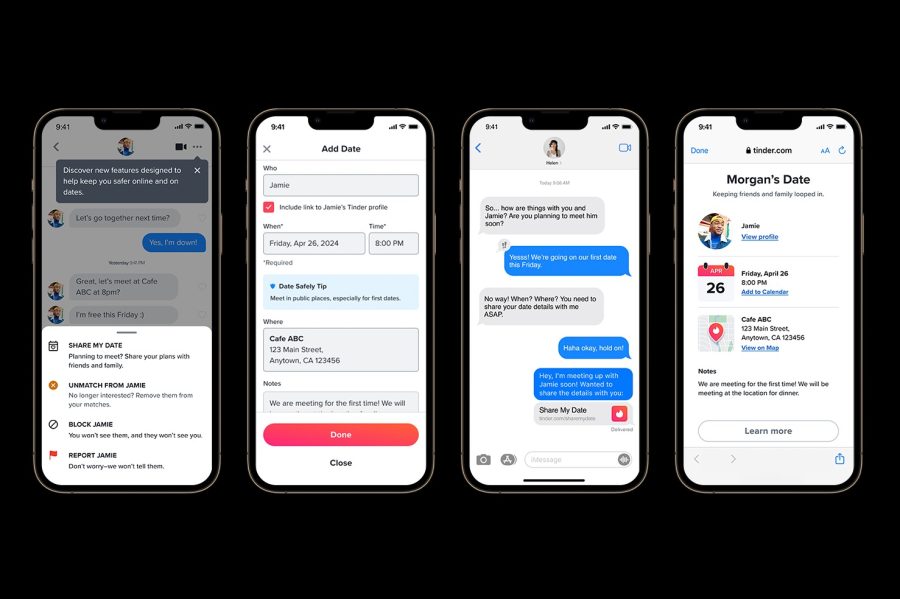
Tinder’s new ‘Share My Date’ feature explained
Ali ReesTech journalist

European Union launches another TikTok probe
Ali ReesTech journalist

AR / VR
Smartphones


We are an award-winning tech website where trusted research and expert knowledge come together
Since 2003, we have helped millions of people learn how to solve tech problems large and small. We work with credentialed experts, a team of trained researchers, and a devoted community to create the most reliable, comprehensive and delightful content on the Internet.
1M
Monthly Readers1.4M
Followers on X35K
ArticlesTrusted
for 20 years5000+
research hrs100+
EXPERT CONTRIBUTORSPopular Topics
Get the biggest tech headlines of the day delivered to your inbox
Explore the latest in tech with our Tech News. We cut through the noise for concise, relevant updates, keeping you informed about the rapidly evolving tech landscape with curated content that separates signal from noise.
Explore tech impact in In-Depth Stories. Narrative data journalism offers comprehensive analyses, revealing stories behind data. Understand industry trends for a deeper perspective on tech's intricate relationships with society.
Empower decisions with Expert Reviews, merging industry expertise and insightful analysis. Delve into tech intricacies, get the best deals, and stay ahead with our trustworthy guide to navigating the ever-changing tech market.