



Latest News
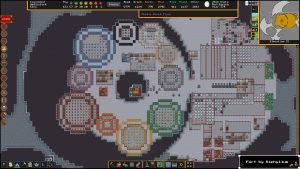
Dwarf Fortress – long awaited Adventure mode comes to one of the greatest games of all time, but what actually is it?
The stunning piece of gaming history that is Dwarf Fortress, a game that you quite possibly have never played before and one that you absolutely should start playing the second you finish reading this page, is finally getting the hugely anticipated Adventure Mode added to its Steam version. For background, in case you have missed…















Artificial Intelligence

The Implication of AI in Crypto Trading
Brad AndersonFormer editor
Cryptocurrency

RBNZ Explores Introduction of Central Bank Digital Currency
The Reserve Bank of New Zealand (RBNZ) has announced that it is exploring the introduction of a central bank digital currency (CBDC), often referred to as "digital cash." This move comes as the RBNZ aims to address the challenges posed...
Radek ZielinskiTech Journalist

GBTC Bitcoin ETF holdings drop before halving
Radek ZielinskiTech Journalist



Entertainment


Technology

Top research center, set up to assess humanity’s future prospects, shuts
A top research institute created with the lofty goals of investigating the 'big-picture questions' and assessing what the future holds for humanity..will now not play a part in that future. The Future of Humanity Institute was founded in 2005 by...
Sophie AtkinsonTech Journalist

AR / VR
Smartphones


We are an award-winning tech website where trusted research and expert knowledge come together
Since 2003, we have helped millions of people learn how to solve tech problems large and small. We work with credentialed experts, a team of trained researchers, and a devoted community to create the most reliable, comprehensive and delightful content on the Internet.
1M
Monthly Readers1.4M
Followers on X35K
ArticlesTrusted
for 20 years5000+
research hrs100+
EXPERT CONTRIBUTORSPopular Topics
Get the biggest tech headlines of the day delivered to your inbox
Explore the latest in tech with our Tech News. We cut through the noise for concise, relevant updates, keeping you informed about the rapidly evolving tech landscape with curated content that separates signal from noise.
Explore tech impact in In-Depth Stories. Narrative data journalism offers comprehensive analyses, revealing stories behind data. Understand industry trends for a deeper perspective on tech's intricate relationships with society.
Empower decisions with Expert Reviews, merging industry expertise and insightful analysis. Delve into tech intricacies, get the best deals, and stay ahead with our trustworthy guide to navigating the ever-changing tech market.